【校友建功立业风采】张祥雨:3年看1800篇论文,28岁掌舵旷视基础模型研究
张祥雨,29岁,现任旷视科技研究院基础模型组负责人。2017年博士毕业于西安交通大学。期间参加微软亚洲研究院联合培养博士生项目,师从孙剑博士和何恺明博士。目前团队研究方向包括高性能卷积网络设计,AutoML与自动化神经网络架构搜索,深度模型的裁剪与加速等。曾在CVPR/ICCV/ECCV/NIPS/TPAMI等顶级会议/期刊上发表论文20余篇,获CVPR2016最佳论文奖,并多次获得顶级视觉竞赛如ImageNet 2015、COCO 2015/2017/2018冠军。代表作包括ResNet/ShuffleNet v1/v2等,在业界得到广泛应用。Google Scholar引用数40000+。入选2019福布斯中国30岁以下精英榜。

张祥雨,旷视研究院base model组负责人,带领组里30多位年轻人为旷视寻找下一个兼具学术和产业价值的算法模型。
在号称平均年龄仅24岁的旷视研究院,28岁的张祥雨已经有leader的样子:每天为团队里来自清华、北大等名校的员工甚至实习生讨论和规划研究方向,他们的研究成果可能会决定公司下一个突破性的基础技术。
实际上,就是这样一个不到30岁的年轻人,在近年来深度学习推动学术和产业两界发展的进程中,虽然身居幕后却享有不世之功:2015年横空出世的ResNet,张祥雨是主要作者之一,负责底层框架和编码,跟一作何恺明打配合;之后又提出ShuffleNet,ShuffleNet凭借轻量级低功耗和高性能,成为旷视拿下OPPO、小米等手机大厂视觉订单的技术核武器。
现在,张祥雨又把研究重点放到了另一个领域:AutoML。AutoML自动化设计、训练AI模型,是用 “计算换智能” 的新范式。如果说手工设计AI模型是坦克的话,AutoML就是飞机,可以极大地加速产品及解决方案在各行业落地,大大降低人力操作成本。
张祥雨认为,70%的AI从业者依然从事着能被机器替代的重复性工作,AutoML这项看似会让AI从业者“失业”的工作,他们从去年就已经开始了,这项工作的意义不仅仅能让AI自动设计AI成为现实,更重要的是,还能够让旷视的产品和方案找到快速落地的捷径,提升整个行业的AI建模和训练效率,真正实现“以非凡科技,为客户和社会持续创造最大价值”。
孙剑的第一个深度学习博士
跟旷视研究院院长孙剑的经历一样,张祥雨也是一名“土生土长”的西安交大人,从本科到博士都在西安交大就读,在大三那年(2011年),张祥雨拿下了美国大学生数学建模竞赛(MCM)特等奖提名奖(Finalist),当时创下西安交大参加该项竞赛以来历史最好成绩。
凭借这次获奖经历,张祥雨获得了后来到微软亚洲研究院实习的资格。获得实习资格的有三人,但最终只有一个人能留下。当时还在微软亚洲研究院担任首席研究员的孙剑给这三人出了一道题:用一个月的时间,将人脸检测的速度提升十倍。
这个任务现在来看比较容易实现,但当时还没有引入深度学习,张祥雨就靠着对模型调参,用了三天左右的时间完成任务,孙剑看过之后当场决定留下张祥雨。
张祥雨之前并没有做科研的经验,这次有意思的实习考验让他初尝到做科研的成就感。他也意识到走学术路线,需要到产业界去锻炼。
到了微软之后,张祥雨加入了视觉计算组,这个小组里的每一位成员名字放在当下来看都是业界大牛:小组负责人孙剑,组员包括何恺明、危夷晨、代季峰、袁路、曹旭东、任少卿等。
在组里,张祥雨尤其擅长编程,并且还是唯一一个会CUDA人。刚加入小组时,就凭借这一技之长成为多个项目的核心成员,比如帮助危夷晨做Head Dance游戏,为袁路做浏览器图片布局等。
2013年,张祥雨面临一个重要选择:博士课题。当时受微软亚洲研究院工作的一些影响,张祥雨倾向于做人脸这个领域。但是导师孙剑果断让他去做深度学习,“孙老师认为Deep learning以后必然会火,他一直非常有前瞻力,我很相信他”。
于是,张祥雨就成了孙剑组里第一个做深度学习的博士生。他做的第一个深度学习相关的工作就是复现深度学习经典论文AlexNet,这篇由Alex Krizhevsky和2018年图灵奖得主Geoffrey Hinton等人完成的论文,让深度学习和神经网络重新崛起。

张祥雨花了两个月的时间对论文进行了复现,包括写完底层全部code。复现AlexNet的经历算是深度学习的入门,之后他的主要工作是做框架、写code。当时深度学习的框架非常少,于是张祥雨干脆自己写了一个,包括CPU和GPU的。
2013年底Caffe问世,为了对Caffe的模型做兼容,张祥雨就把接口也改成Caffe一样,还起了个名字叫Caffe Pro。这份code关键的一个亮点是支持图优化,支持多卡,这为后来ResNet的诞生打下了基础。
ResNet的诞生
在完成这份code以后,孙剑就把何恺明、任少卿、张祥雨拉到一起做深度学习,在组队之前,何恺明做了图像重建和哈希计算,任少卿做人脸。
经过一年的磨合,“何张任”组合在孙剑的带领下小有所成,ECCV、TPAMI等国际视觉会议的论文中开始出现这三个二十多岁中国人的名字。这几位年轻人真正爆发是在2015年。当时包括谷歌、百度在内的大厂都在参加ImageNet大规模视觉识别挑战赛,当时人类识别图像正确分类的误差率为5.1%,谁能打破5.1%,就代表在这一领域机器超越了人类,而2014年最好的成绩是6.67%,由谷歌创造,但依旧没能实现5.1%,百度也积极尝试,试图第一个打破5.1%。
“何张任”组合决心跟大厂们硬刚一下
事实证明,想要突破大厂们都还没打破的记录并非易事。主要是由于神经网络想提升能力就得持续加深,但一加深就不收敛,导致实验结果很不理想。
有一天,张祥雨突然意识到收敛的问题跟梯度消失有关系,如果做一些独立性假设的话,是可以推出一套参数初始化的法则,让梯度消失的问题解决。因此他推导出一组公式,后来在微软内部命名为“xiangyu初始化法”。
接着,“何张任”组合又引入一种新的修正线性单元(ReLU),将其称为参数化修正线性单元(PReLU),并且通过对修正线性单元的非线性特征进行直接建模,推导出一种符合理论的初始化方法,并直接从头开始训练网络,将其应用于深度模型的收敛过程。
这种方法应用到比赛之后结果出炉:错误率已降低至4.94%,超越人类!不过,张祥雨认为,打破记录确实可以长点脸,但是并不足以证明AI直接超过了人类。他们发现,挑战到了后面就完全变成了一个工程问题,成了怎么用有限的资源训练起来更大的网络。
“其实我个人是非常不满意的,因为虽然打败了人类,但更多是一个噱头,我们也知道这些方法并不很work,主要是靠调参和堆模型。”张祥雨说。
张祥雨又重新复盘,他发现2014年的ImageNet冠军谷歌GoogLeNet只用了一点几个G的复杂度就实现了非常高的准确度,他认为GoogLeNet可能是其他几个模型的必经之路。
经过几个月的研究,张祥雨发现,GoogLeNet最本质的是它那条1x1的shortcut。“说白了,可以把它简化到最简单,可以发现GoogLeNet只有两条路,一条是1×1,另一条路是一1x1和一个3x3”。
到底是什么在很低的复杂度上支撑起了GoogLeNet这么高的性能?张祥雨猜想,它的性能由它的深度决定,为了让GoogLeNet 22层的网络也能够成功地训练起来,它必须得有一条足够短的直路。
基于这个思路,张祥雨开始设计一个模型,利用一个构造单元不断的往上分,虽然模型结构的会非常复杂,但是不管怎么复杂,它永远有一条路,但深度可以非常深。“我认为这种结构就可以保持足够的精度,同时也非常好训练,我把这个网络称为分形网。”
张祥雨把分形网的成果跟何恺明商量,何恺明的意见是:结构还是过于复杂。“复杂的东西往往得不到本质”,何恺明一语中的,并建议进一步对这个模型进行化解,用它的一个简化形式。
于是张祥雨又延伸之前的假设:最短的路,决定容易优化的程度;最长的路,决定模型的能力,因此能不能把最短路尽可能的短,短到层数为零?把最深的路,无限的变深?
基于这个思路,诞生了ResNet,有一条路没有任何参数,可以认为层数是0。
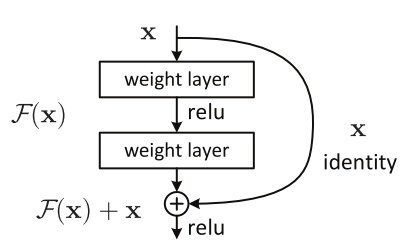
“何恺明老师的研究思路对我启发很大,从纷繁的结构中找出最work的本质属性,这种极简化的思想是ResNet的核心,并且使得ResNet有很强的泛化能力,任何人都可以在基础上做各种修改,能启发别人的研究。”张祥雨说。
ResNet提出后,“何张任”组合打比赛,张祥雨负责code部分,当年一下取得5项挑战赛第一,“何张任”组合在导师孙剑的指导下获2016年CVPR最佳论文奖,迄今单篇引用超20000,ResNet也成为计算机视觉领域最流行的框架之一。
从ShuffleNet到AutoML:年轻人拿起了公司战略的斧头
2016年7月,孙剑加盟旷视,担任首席科学家,张祥雨也在博士毕业后追随导师,开启了在旷视工作的历程。
而刚刚来到旷视,张祥雨便遇到了一个非常严峻的问题:产品落地较为困难,特别是在手机领域,实在没有一个靠谱的网络可以去依赖。就在这时,作为论文评审的张祥雨审了一篇论文,这篇论文是Keras作者Fran?ois Chollet等人写的,张祥雨比较认可论文里所提到的Xception网络,他敏锐地意识到这个idea可以用于轻量级网络设计,“以后绝对可以用到移动端”,是未来可发展的一个方向,并且还给了这篇论文一个Oral。
虽然这篇论文后来被另外的评审给否了,但是给张祥雨带来非常大的灵感和启发。不久之后,张祥雨和同事周昕宇开始一起研究移动端模型,在前期的工作基础上提出了一个高性能模型,二人不谋而合,同时想到了一个想法——Shuffle。
二人在努力合作后,以共同一作的身份中标了CVPR,并且不论是从实验结果还是对业界的影响上,ShuffleNet都是成为移动端网络模型的杰出代表之一,2017年苹果推出带有3D人脸解锁功能的iPhoneX ,安卓手机厂商随后跟进,包括VIVO、小米还有锤子手机的人脸解锁技术,其实就是ShuffleNet在背后提供计算,能够让各种配置不一的手机都能实现毫秒级人脸解锁。
2018年,作为ShuffleNet的升级版,ShuffleNet V2 为ECCV 2018 所收录。而在刚刚落幕的VALSE 2019中,ShuffleNet V2 一举斩获拿下 “VALSE 2018 年度杰出学生论文奖”。其论文技术及一套轻量高效模型方法论的提出,有迁移通用能力的同时,还兼具理论实践意义和学术借鉴意义。
技术有时候是为了跟上业务需求,但对旷视和张祥雨而言,需要做出一些超前的底层技术,能够让技术预见到公司未来几年战略需求,同时还能拉开跟对手的差距,是最理想的情况,但这对一个年仅28岁的年轻人来说并非易事。
在关键时刻,导师孙剑的建议起到了非常重要的作用。当年张祥雨还是博士生时,孙剑建议他做深度学习;2017年,孙剑建议他做高性能网络,2018年,孙剑建议做AutoML。
AutoML领域的研究,之前一直是被国外如谷歌、微软等大企业“垄断”的状态,谷歌已经推出Cloud AutoML产品,走得非常前面,既能让公司业务有很好的落地路径,也给竞争对手造成了不小压力。
经过一年多的研究,今年4月,张祥雨作为共同一作发表了旷视的第一篇AutoML技术论文。论文提出的超网络包含所有子结构,只训练一次,所有子结构便可以直接从超网络获得其权重,无需从头训练。实验结果表明,在精度、内存消耗、训练时间、模型搜索的有效性及灵活性方面最优,超过了谷歌、Facebook等公司AutoML的成绩。
模型自动化是当前AI技术的一个趋势和未来浪潮,也成为旷视人工智能框架Brain++的核心要素之一,拉通从数据到部署的算法全要素、全流程生产,旷视研究院的Brain++ AutoML将成为战略升级的重要技术支撑。可以说,张祥雨的工作直接影响着公司未来业务。
大学也刷题,三年看1800篇论文
不同于旷视研究院常被提及的各类金牌得主、高智商神童,即便自己的学生生涯始终保持着Top1的绩点,张祥雨也从不认为自己是“神童”型选手。“我资质真的一般,都是拼命刷题刷的。”
那么在高智商选手云集的AI领域,接连在CVPR、NIPS等顶会“中奖”的人为什么是他?28岁就能拿起斧头为公司开辟基础算法新路的人,为什么也是他?
在旷视研究院的工区,张祥雨的工位很难不被注意到,新智元看到在他桌子上高垒着两摞纸,张祥雨说这是他最近在看的论文。

张祥雨工位上的论文
“从2016年到现在,我已经看了1800篇了,看过的都用软件记下来”。粗略算一下,张祥雨平均每天看两篇论文。而这只是他每天做实验、管理团队之余,停歇片刻去做的事情。
今年,4月16日,北京智源人工智能研究院发布“智源学者计划”,公布了首批智源青年科学家候选人名单,张祥雨是九位候选人中最年轻的一位。
作为一位过来者,张祥雨也经历了从求学到求职、从研究团队的组员到组长的成长历程。在新智元的专访过程中,张祥雨也为年轻的学生或初入职场的新人提出了两个建议:脚踏实地以夯实基础和开拓视野以保持前瞻,他认为这两点是AI领域从业者的必要素质,而他一直身体力行。
(原文刊载于和讯网,文章版权归原作者及原出处所有。)
原标题:孙剑首个深度学习博士张祥雨:3年看1800篇论文,28岁掌舵旷视基础模型研究
文章链接:https://news.hexun.com/2019-04-22/196906796.html




